While I was visiting Russia last year, I was alerted to a thread on the TouchDesigner forums about some people who had found touchFluid on Github and were struggling to get it to work. Part of that had to do with me omitting some files from the public repo due to the licensing language on those files (which I was later told is out of date and will be revised), but they were also getting stuck on setting up their CUDA environment correctly. I don't blame them, Touch is only compatible with an older version of CUDA and is difficult to install on newer systems. You have to jump through a bunch of hoops to get an old version of VS which still isn't quite old enough so you still have to force CUDA to talk to it so you can build a dll. I couldn't work on it remotely anyway since my laptop is a Mac.
On a whim one morning, I tried transcribing my code to GLSL in Touch. It went surprisingly fast and I got it working in a couple hours. It was also about four times faster.
I made a tough call to drop supporting CUDA and move forward with GLSL. The main thing I lost was the potential to implement Ted's wavelet turbulence on the GPU. This was something I wanted to do as soon as I got Stam's stuff working, but the math and engineering involved was making it slow sailing for this Bachelors of Fine Arts noggin. With an installation deadline looming, I wasn't making progress on the art side fast enough either. Shader development time is faster, they're more portable, easier to read (more "hackable"), and are more performant given my circumstances.
CUDA is incredibly powerful and has the potential to completely maximize NVIDIA GPU's. The problem essentially came down to my desire to continue learning its nuances.
Writing kernels in CUDA is pretty easy, but writing fast kernels is a lot trickier. A common technique to speed up bandwidth is to use their concept of shared memory, which is essentially just a cache that performs 100x faster than reading from the GPU's global memory. It makes sense, but the code is ugly as sin and further obfuscates the already confusing thread/block/grid indexing scheme one is forced to use when working with thousands of cores. My code could have benefited from shared memory because many kernels use a Von-Neumann grid to look up neighboring values, causing about 4x redundant global memory reads. The problem was exacerbated by the fact that my data was stored linearly, so I needed huge strides to look up neighbors above and below the current cell- the image width * 4 (the rgba channels). According to this official blog post about shared memory, bandwidth drops by 80% after a stride of just 4 and continues to decline after that. This is the graph that convinced me to at least try shaders:
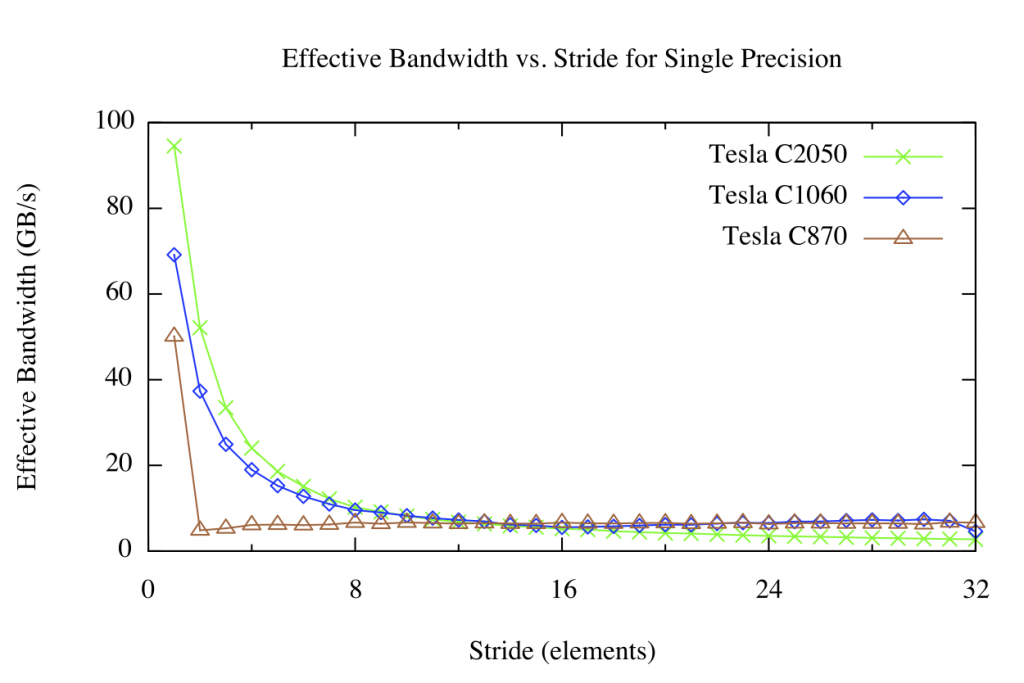
The speed boost I suspect comes from not having to deal with strides at all, instead encoding all the data into textures, which are optimized for random lookup.
Simulating using shaders is hardly a new thing. That, along with a few other oddities steered me away from them early on. You have to always be mindful that you are dealing with textures as a data structure so setting the filtering and format appropriately is crucial. They're also notoriously cryptic to debug, although that's slowly changing. Those are minor gripes when taking into account their ubiquity and accessible parallelism for visual media in general. The paradigm continues to advance with new hardware supporting things like dynamic tessellation and multiple camera matrices, and the community of users has never been stronger.
A couple months ago I wrapped everything up into a single tox, TouchDesigner's format for sharing snippets and single components, and put it on the forums to positive feedback. The CUDA repo lives on as a fork, but I'll continue working with the shader version from here on out.


